生成AIの普及により、検索の前提は静かに、しかし確実に書き換えられています。LLMO(大規模言語モデル最適化)とは、ChatGPTなどの生成AIに引用・参照されやすい情報構造を設計する概念です。
従来のSEO(検索エンジン最適化)が検索順位を対象とするのに対し、LLMOはAIが生成する回答内での可視性を最適化します。
私たちは検索順位を比較するのではなく、AIが生成した要約を前提に意思決定しているのです。
ChatGPTにおいて1位に位置するReddit、さらにGoogleとの公式情報連携という事実は、この変化が一過性ではないことを示しています。
検索体験の構造転換は、すでに不可逆な段階に入っています。本記事では、評価構造の変化と企業が取るべき戦略的含意を、LLMO的視点から体系的に整理します。
1. LLMはどのような情報構造を優先するのか
生成AIの普及によって、情報評価の基準は順位から生成可能性へと移行しつつあります。従来の検索エンジンは、ページ単位での評価とリンク構造を軸にランキングを提示してきました。
しかし、LLMは順位を提示するのではなく、膨大な学習データから確率的に最適化された回答を生成します。この違いは単なるUIの差ではなく、評価単位そのものの転換を意味します。
LLMOの本質は、AIがどの情報を引用しやすいかではなく、AIがどの構造を信頼推定しやすいかを理解することにあります。
1.1 従来型検索アルゴリズムとの決定的な違い
従来の検索はページ単位で評価され、被リンクやキーワード一致度、ドメイン評価で順位付けが行われていました。ユーザーは候補を比較して情報を選択します。
一方、LLMは順位を提示せず、膨大な学習データから統計的に妥当性の高い文章を生成します。評価対象はページではなく、言語パターンや文脈構造です。この違いは情報流通の前提を根本から変え、LLMO設計の出発点です。
1.2 LLMの学習プロセスと信頼推定
LLMは公開Webの大規模テキストを事前学習し、人間のフィードバックで精度を調整します。明示的な信頼スコアはないものの、文脈の一貫性や論理整合性、多視点統合の自然さが間接的に重み付けされる仕組みです。
LLMは信頼できる情報を評価するのではなく、信頼されやすい構造を再現します。LLMOでは、どの構造が学習上優位に働くかの理解が不可欠です。
1.3 LLMが優先しやすい4つの情報構造の特徴
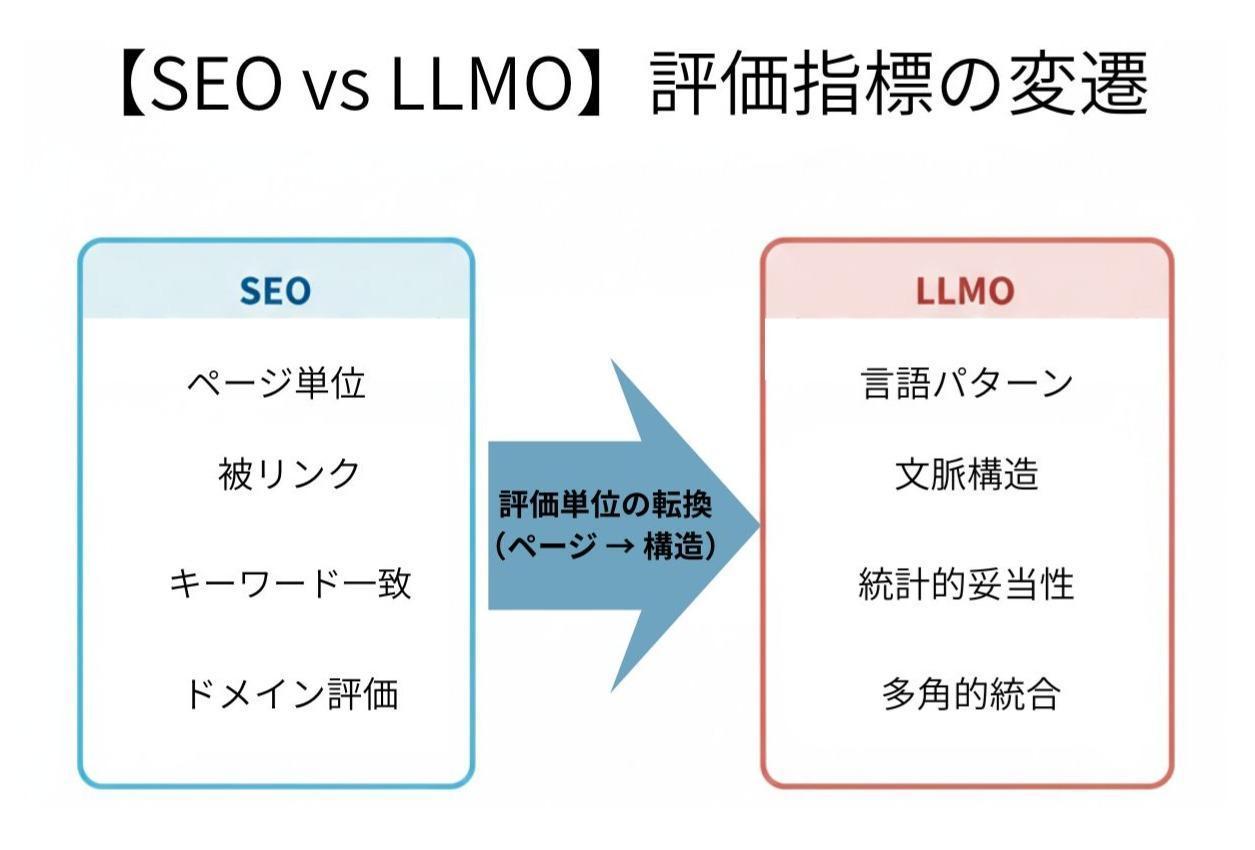
以下の図は、従来の検索エンジン最適化(SEO)から、AI時代の大規模言語モデル最適化(LLMO)へと、情報の評価基準がどのように変化しているかを示したものです。
中央の矢印は「評価ユニットの転換(Evaluation Unit Shift)」を意味しており、評価の対象が「ページ」という単位から情報の「構造・文脈」へとシフトしていることを表しています。
また、LLMは単に情報量が多い媒体を優先しているわけではありません。重要なのは、生成時に再構成しやすい構造を備えているかどうかです。
文脈が連続していること、複数視点が併存していること、評価シグナルが可視化されていること、そして自然言語としての多様性が確保されていること、これら4つの要素が組み合わさることで、統計的整合性を保った回答を生成しやすい環境が形成されます。
LLMOの観点では、媒体単位ではなく構造単位で優位性を分析することが必要です。
- 複数視点が並列する構造:異なる立場や経験が同時に存在する情報は、LLMが統合的に回答を生成しやすくなります。単一の断定記事よりも、賛否や補足情報が併存する議論空間の方が再構成可能性が高く、引用されやすい環境を形成します。
- 集合知的な評価シグナルの存在:支持・反証・評価傾向などのメタ情報が可視化されている環境は、AIが統計的に信頼度を推定する際の補助線です。評価履歴が言語パターンに反映されるため、LLMO戦略において重要な戦略対象です。
- 長期的な議論ログの蓄積:単発の記事よりも、時間軸を伴った議論データは文脈の継続性を内包しています。これにより、LLMが自然な説明を構築しやすく、部分引用の精度も向上します。
- 実体験ベースの自然言語データ:企業公式情報は整理されますが、経験情報の多様性は限定的です。LLMは実体験ベースの語彙・文脈パターンを学習することで、多様で再構成可能な回答生成が可能となります。
1.4 LLMO視点での含意
LLMOでは、自社コンテンツ単体の最適化だけでなく、AIが参照しやすい情報構造全体を把握することが重要です。
従来型SEOの延長でキーワード網羅や内部リンク強化を行うだけではAI回答内での可視性は保証されません。評価単位がページから構造に移行している以上、設計対象も構造でなければなりません。
外部プラットフォームとの接続や集合知との関係性まで含めた戦略設計が、LLMO時代の競争優位につながります。
2. RedditはなぜLLMと親和性が高いのか
LLMが優先しやすい情報構造を具体的に満たすプラットフォームとして、近年顕著な存在感を示しているのがRedditです。
同サービスは単なるSNSではなく、投票アルゴリズムとテーマ特化型コミュニティを基盤とする集合知構造を備えています。
この設計は、多視点性、評価シグナルの可視化、時系列ログの蓄積、実体験ベースの言語密度といった条件を同時に満たす点が特徴です。
さらにGoogleとの公式情報連携という事実は、その影響範囲が検索基盤にとどまらない可能性を示唆します。本章では、Redditの構造的優位性とLLMとの適合性を多角的に分析します。
2.1 Reddit構造とLLMの適合性
LLMが優先しやすい情報構造の条件を踏まえると、特定のプラットフォームが構造的優位性を持つ理由が見えてきます。その代表例が米国発の掲示板型プラットフォームであるRedditです。
同サービスはテーマ特化型コミュニティと投票アルゴリズムを中核に設計されており、集合知と実体験データが高密度で蓄積されます。この構造こそ、LLMが再構成しやすい言語空間を自然に形成する基盤です。
2.1.1 投票アルゴリズムと集合知的評価構造
Redditの中核には、投稿やコメントに対するアップボート/ダウンボート機能があります。単純な時系列表示ではなく、コミュニティから支持された発言が上位化される仕組みです。
この評価履歴は、どの言語パターンが支持を集めやすいのかという傾向を可視化します。LLMは明示的に投票数を参照しているわけではありませんが、支持されやすい言語構造は学習過程で間接的に重み付けされる傾向が考えられます。
LLMOの観点では、この集合知的評価構造が持つ示唆は大きいといえます。
2.1.2 可視化された評価がもたらす信頼推定補助
評価数や支持傾向が明示されている環境では、単なる投稿量ではなく、コミュニティによる選別結果がデータとして蓄積されます。この構造は、どの発言が議論に耐え、再利用されやすいかを示す指標です。
LLMは信頼性を直接判断しているわけではありませんが、支持されやすい文脈や言語パターンは統計的に強化されやすい傾向が示唆されます。結果として、評価が可視化された構造は、信頼推定の補助線として機能します。
2.2 反証と補足が同時に存在する議論空間
Redditでは一つの投稿に対して賛否両論や補足情報を即座に追加することが可能です。反証や体験談が並列的に存在するため、議論は単一視点に固定されません。
この多層的な構造は、LLMが多面的な回答を生成する際の素材として適しています。単一の断定記事よりも、賛否が可視化された議論ログの方が、統合的な説明を組み立てやすい傾向があると考えられます。
LLMO視点では、この対話的構造自体が引用優位性を生む要因です。
2.2.1 Subredditによるテーマ特化型クラスタ構造
RedditはSubredditと呼ばれるテーマ特化型コミュニティによって構成されています。各Subredditは特定領域に関心を持つユーザーが集まり、議論や情報共有を行う場として機能します。
この構造により、トピックごとの言語パターンが高密度で蓄積され、専門性の高い情報クラスタが自然に形成可能です。ノイズが分散されることで、LLMにとって再利用しやすい文脈集合が生成される点は、LLMO観点から見ても重要な特徴です。
2.2.2 専門性の自然発生
Subredditでは公式メディアではなくユーザー主体で議論が進みますが、長期的な蓄積により専門的知見が集約される傾向があります。
特定テーマに継続的に参加するユーザーが存在することで、暗黙知や実務的な知識が共有される環境です。このような自然発生的な専門性は、画一的な公式情報とは異なる言語多様性を生み出します。
LLMは多様な文脈を学習するため、こうした環境は再構成可能性の高いデータ源です。
2.2.3 時系列ログの厚み
Subreddit内では議論が時系列で蓄積され、過去の投稿やコメントが参照可能な状態で保存されます。この履歴構造は、議論の変遷や再評価の過程を含むため、単発記事よりも文脈密度が高いことが特徴です。
LLMが自然な説明を生成する際には、こうした時間軸を伴うデータが有効に機能します。LLMOの観点では、情報の量よりも文脈の厚みが再利用性を左右する点に注目する必要があります。
2.3 Googleとの公式情報連携の意味
2024年、GoogleとRedditはデータ提供に関する公式提携を発表しました。この連携により、GoogleはRedditコンテンツへの効率的なアクセスを確保したとされています。
これは単なる検索結果表示の最適化にとどまらず、ユーザー生成コンテンツが検索基盤に組み込まれる構造的変化を意味します。検索基盤と生成基盤の接続が進むなかで、この連携はLLMO戦略にとって無視できない要素です。
2.3.1 検索結果への影響
Google検索結果においてRedditスレッドの表示頻度が高まっているとの観測もあります。これはアルゴリズム上、実体験ベースのユーザー生成コンテンツが評価対象として強化されている可能性を示唆します。
従来はメディア記事が優位だった領域において、議論ログが上位表示されるケースが増えている点は注目に値します。LLMO視点では、検索基盤側の評価変化がAI引用環境にも波及すると考えるべきです。
2.3.2 AI引用環境への波及
検索基盤と生成基盤が接続されることで、Reddit上の言語データは間接的にAI回答環境へ影響を与える構造になります。
検索結果で可視化される頻度が高まれば、学習データとしての存在感も強化される可能性があります。
LLMは特定ドメインを意図的に優遇しているわけではありませんが、構造的に再利用しやすい環境は結果として引用優位性を持ちます。この連鎖構造を理解することが、LLMO戦略の前提です。
3. 企業はReddit構造をどう戦略に組み込むべきか
Redditの構造がLLMと親和性を持つことが事実であるならば、企業はそれを外部環境の変化として眺めるだけでは不十分です。
生成AIは、孤立したページではなく、議論が蓄積された言語空間を横断的に再構成します。つまり競争の単位は、サイト単体から情報構造全体へと移行しています。
この変化は一時的なトレンドではなく、長期的な構造転換です。本章では、Reddit構造を前提に、企業がLLMO戦略へどう組み込むべきかを整理します。
3.1 LLMO戦略への転換点
RedditがLLMと構造的親和性を持つ以上、企業はこの動向を傍観することはできません。
求められるのは、自社サイト内部の最適化だけに閉じた発想から、AIが再利用しやすい言語空間とどう接続するかという視点へ転換することです。LLMは順位そのものよりも、統合可能な言語構造を重視します。
外部集合知との関係性設計を含めて初めて、生成環境での可視性が高まります。
3.1.1 自社最適化中心主義からの脱却
従来のSEOは、自社ドメイン内の品質向上と内部構造最適化を中心に発展してきました。しかしLLM時代では、評価単位がページから言語クラスタへ移行しています。
自社サイト内で情報を完結させるだけでは、AI回答内での存在感は十分に確保できません。着目すべきは、自社情報がどの外部議論空間で言語化され、どの文脈で再解釈されているかを把握することです。LLMOでは外部構造との接続設計が不可欠になります。
3.1.2 AIはURLではなく言語パターンを統合する
LLMは特定のページをそのまま引用するのではなく、複数の情報源から抽出した言語パターンを統合して回答を生成します。したがって問われるのは順位ではなく、どの言語クラスタに情報が属しているかという点です。
孤立した情報は再利用されにくく、議論の中で繰り返し言語化された情報ほど統合対象になりやすい傾向があります。
3.1.3 外部言語空間との接続設計
Redditのような集合知空間で形成される論点や表現は、生成AIにとって再構成しやすい素材です。自社情報がこうした空間と接続していない場合、AI生成環境での出現確率は相対的に低下します。
外部言語空間との接点を設計することが、LLMOの実務上の出発点になります。
具体的には、
- 自社ブランドや製品に関連するSubredditを特定し議論の論点を定期的にモニタリングする。
- 自社コンテンツが扱うテーマと重複する頻出論点をReddit上で確認しコンテンツ設計に反映させる。
- 外部から言及・引用されやすいように自社ページの構造と表現を議論空間の語彙に近づける。
といったアプローチが実務的な出発点となります。Redditへの直接投稿よりも、まず「読む・分析する」段階から始めることが現実的です。
3.2 Redditを戦略対象として再定義する
以下の図はChatGPT引用上位ドメインにおけるRedditの優位性を表したものです。
ChatGPTがどのドメインを引用しているのかを見ると、単なる人気順位ではなく、LLMが再構成しやすい構造を持つ媒体が上位に現れていることが分かります。
Redditは突出しており、その背景には投稿・投票・評価が循環する信頼可視化の仕組みです。
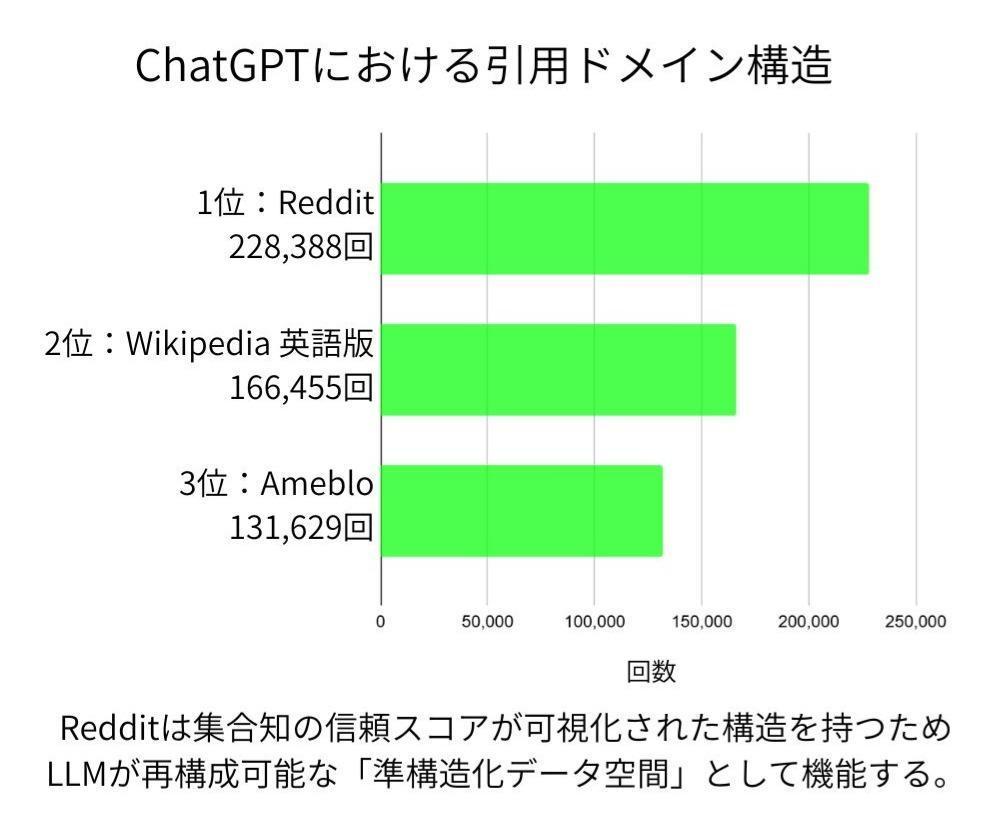
Redditが引用上位にある背景には、情報量の多さに加え、集合知の評価が可視化されている構造的特徴が寄与していると考えられます。
この信頼スコアの構造がLLMの統計的重み付けと高い親和性を持つため、RedditはAIにとって準構造化された信頼データ空間として機能しています。
多くの企業はRedditを口コミ確認や風評監視の場として扱っています。しかしLLMO視点では、その理解は不十分です。
Redditは単なる評判空間ではなく、AIが再構成しやすい自然言語データが蓄積される構造空間です。どの論点が支持され、どの表現が繰り返されているかを分析することは、生成AI時代の需要理解に直結します。
Redditはもはや監視対象ではなく、戦略設計対象として再定義されるべきです。
以下の図は、Redditにおけるユーザーの活動が、どのようにAIの回答精度や信頼性に接続され、循環しているかを示したものです。
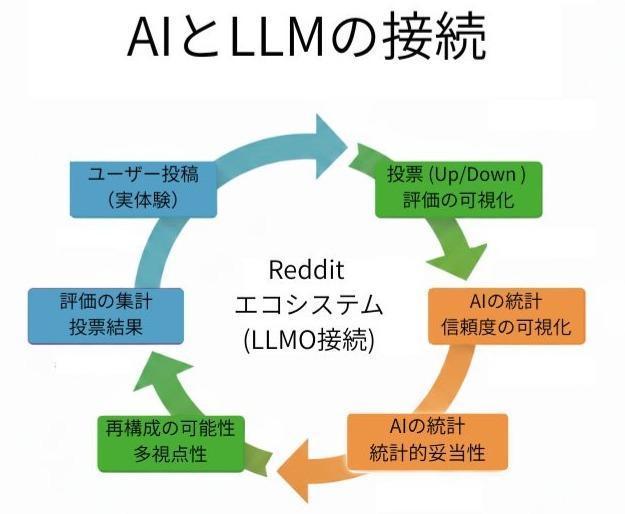
ChatGPTなどのAIがRedditを頻繁に引用するのは、このエコシステムの中に「人間による検証」と「AIによる統計的処理」が高度に融合した信頼のループが確立されているからだと言えます。
この構造的優位性は、GoogleとOpenAIの2社がRedditとデータ連携契約を締結したという事実によっても裏付けられます。
現在のAI検索(LLMO)においてRedditが極めて重要な情報源(構造資産)であることの証左といえるでしょう。
3.2.1 議論傾向の構造分析
Reddit上のスレッドには、賛否、補足、体験談が多層的に蓄積されています。これらはユーザーが本質的に求めている情報の構造を示す、貴重な一次データです。単なる感想として処理するのではなく、論点の分布や頻度を構造的に分析する視点が重要です。
3.2.2 コンテンツ設計への還元
抽出された論点や表現パターンを自社コンテンツへ反映させることで、AIが再利用しやすい構造を形成できます。キーワード最適化だけではなく、議論単位で設計することが、引用可能性を高める実務的アプローチです。
3.3 Google連携を前提とした統合設計
GoogleとRedditの公式連携は、ユーザー生成コンテンツが検索基盤へ統合される構造変化を示唆します。これは検索表示の話にとどまらず、検索と生成の接続強化を意味します。
企業は順位だけでなく、議論空間内でどのように自社情報が語られているかまで視野に入れる必要があります。SEOと生成最適化を分断せず、統合的に設計する視点が求められます。
3.3.1 検索と生成の接続強化
検索基盤に組み込まれた集合知は、生成環境にも影響を与える可能性があります。検索上で可視化される議論は、LLMが参照する言語データとして蓄積され得ます。検索対策と生成対策が接続する時代が、すでに始まっています。
3.3.2 統合戦略としてのLLMO
従来のSEO施策とSNS施策を分業的に扱う体制では、構造変化に対応しきれません。LLMOは、検索流入とAI回答内引用の双方を射程に入れた統合戦略です。言語空間全体を俯瞰した設計こそが、持続的な競争優位を生み出します。
4. AI引用対策の実践設計モデル
AIに引用されるかどうかは偶然ではなく、構造設計の帰結です。検索順位の最適化だけでは、生成AI時代の情報優位性は確保できません。いま評価されているのはページではなく、再構成可能な言語構造です。
この変化は一過性のトレンドではありません。本章では、結論提示の順序、根拠の明示、具体例の接続、集合知との統合までを体系化し、LLMに再利用されやすい論点設計モデルを提示します。AI引用を前提にした実践的な構造戦略を具体化します。
4.1 AI引用は偶然ではなく構造設計である
AIに引用される現象は、偶発的な露出ではありません。LLMは大量の言語データを横断し、再構成可能性が高い情報を統合します。そのため引用は、ページの出来栄えというよりも、構造的整合性の帰結です。
問われるのは、AIが理解・分解・再構築しやすい論点設計になっているかどうかです。LLMOにおける引用対策とは、検索順位対策の延長ではなく、言語構造の最適化です。本章では、その具体設計モデルを提示します。
4.1.1 再構成されやすい論点設計
AIは文章全体をそのまま利用するのではなく、論点ごとに整理された構造を優先的に扱います。LLMOでは「人間に読みやすい」だけでなく、AIが再構成しやすい構造であるかが評価軸です。
具体的には、結論→根拠→具体例の順で整理されたコンテンツほど、LLMが理解・再構成しやすく、生成回答に反映されやすくなります。段落ごとの見出しや論点の明示は、AIが論理構造を把握する際の補助として機能します。
以下の図はLLMが処理しやすい論点構造の基本モデルです。
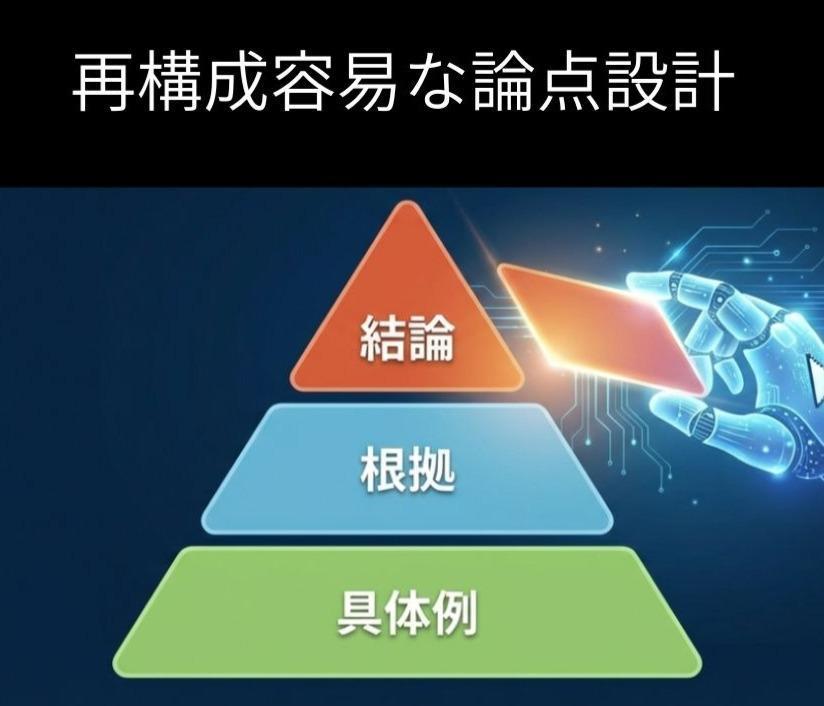
上図は、結論→根拠→具体例という構造が、LLMの再構成コストをどう低下させるかを示したものです。
4.1.2 結論先出しと論拠分離
LLMは文章を逐語的に読むのではなく、意味ブロック単位で分解し、再構成可能性の高い部分を抽出します。
結論が文末や段落の途中に置かれていると、LLMが意味の重心を特定するコストが上がり、引用候補としての優先度が下がります。実装上のポイントは2点です。第一に、各段落の冒頭1文で結論を完結させること。
第二に、その根拠・補足・具体例を後続の文で段階的に展開することです。この構造により、LLMが段落単位で意味を抽出できるようになり、部分引用の精度と頻度が向上します。
結論先出しは読者への配慮ではなく、AIへの再構成コスト削減を目的とした設計判断として捉えることが重要です。
4.1.3 文脈の自己完結性
LLMは回答生成の過程で文章を分解し、意味単位ごとに再配置します。そのため、前段を読まなければ成立しない構造は、断片化された瞬間に意味が不安定になります。
文脈依存度が高い文章ほど再利用の難易度が上がり、引用候補としての優先度も低下しやすくなります。これは、意味の自立性が担保されていないためです。各論点が単体で完結する構造は、再構成耐性を持ちます。
本質は可読性の向上ではなく、「部分再利用を前提とした設計思想」に転換することです。自己完結性を備えた文章は、AIが安全に抽出できる引用単位を形成します。これはLLMOにおける基礎条件といえます。
以上3つの原則を踏まえると、LLMOは抽象概念ではなく、実装可能な設計フレームとして整理する必要があります。構造設計・再構成耐性・集合知接続を統合すると、実践は次の4ステップに体系化できます。
以下は、AI引用を前提とした設計モデルの全体像です。
| 設計ステップ | 実施内容 | AIへの効果 |
|---|---|---|
| 1. 結論提示 | 各セクションの冒頭で結論を明示。 | AIが最優先で要点を抽出できる。 |
| 2. 論拠分離 | 根拠や補足を段落単位で明確に分ける。 | 分解コストが下がり、引用確率が上がる |
| 3. 自己完結性の確保 | その段落単体でも意味が通じるように書く。 | 部分引用や再構成が容易になる。 |
| 4. 集合知との接続 | 頻出論点や専門的な議論と紐付ける。 | 信頼できる一次情報源として扱われる。 |
この4ステップは独立した施策ではなく、「再構成耐性の確保」と「統計的妥当性の獲得」という2軸に収束します。前半は内部構造の最適化、後半は外部言語空間との接続設計です。
LLMOとは、文章品質の向上ではなく、言語構造をAIの重み付け空間へ適合させるプロセスに他なりません。
4.2 集合知との接続と引用価値
RedditやGoogle公式情報のように、多数の視点や反証が蓄積された空間は、言語クラスタとして高い安定性を持ちます。
単一の主張よりも、賛否や補足が共存する構造のほうが意味の揺らぎが小さく、統計的重み付けの基盤として扱いやすいからです。
ここでは情報量より、構造の安定性が問われ、特にRedditは投稿・投票・評価が循環する信頼可視化モデルを持ち、ChatGPT引用率上位に位置しています。
その背景には、この構造的特性が一因として働いている可能性があります。段階化された評価シグナルが、LLMの推論過程における重み付けロジックと整合しているため、問われているのは権威の参照ではなく、言語空間全体への構造的接続です。
4.2.1 議論キーワードの抽出
頻出論点や繰り返し用いられるフレーズは、集合知空間における意味の重心を示します。これらは単なるキーワードではなく、言語クラスタを形成する構造単位です。
LLMは出現頻度と文脈の安定性を手がかりに、意味の妥当性を推定します。自社コンテンツ内でこれらの論点を整理し、再定義し、体系化することで、外部集合知との構造的接続が生まれます。
優先すべきは語句を追加することではありません。論点単位で意味整合を確保することこそが、LLMO実装の中核となります。
4.2.2 評価シグナルの明示化
集合知空間では、賛成・反対・補足・条件付き意見が可視化され、多層的な構造が言語の安定性を高め、統計的重み付けを可能にしています。単一視点による断定は反証可能性を欠き、構造としては脆弱です。
自社コンテンツでも、メリット・デメリットや異論を明示することで、多面的な評価軸を持たせることが可能です。多層構造は再構成適性を高め、引用確率の向上につながります。
これは単なるバランス配慮ではなく、評価シグナルを設計する戦略的アプローチです。
4.3 検索と生成を横断する設計思想
現代のSEOでは、検索結果と生成AIの回答が横断的に最適化されることが重要です。検索上位表示に必要な構造化データと、生成AIが参照しやすい論点設計を同時に組み込む横断設計が求められます。
SERP分析で得られた主要論点を抽出し、Redditなどの集合知情報で補完、結論・根拠・具体例を論理的に配置することで、検索ユーザーと生成AI双方に価値のある情報提供が可能になります。
生成AI時代において、この設計思想は最適化の必須条件です。
4.3.1 構造設計をKPIに組み込む
ページPVや順位だけでなく、AI回答内での言語出現頻度や引用傾向も観測指標に加えることが重要です。従来の評価軸だけでは構造変化に対応できず、戦略の柔軟性が損なわれます。
構造設計をKPIに組み込むことで、AI時代に適応した効果測定が可能です。
4.3.2 構造的変化への適応
生成AIの普及は一時的現象ではなく、情報消費の流れは恒久的に変化しています。そのため企業は構造設計を前提に戦略を再構築する必要があり、LLMOはその変化へ適応するための具体的な実装概念として機能します。
5. まとめ
本記事では、RedditとGoogleの連携を起点に、LLMO時代における企業の情報戦略を体系的に解説しました。
LLMが優先する情報構造の特徴、Redditの構造的優位性、企業が取るべき戦略転換、そしてAI引用を前提とした実践設計モデルまでを提示しています。
評価単位がページから構造へと移行する継続的な変化において、自社最適化中心から外部言語空間との接続設計へと転換することが、持続的な競争優位を生み出します。
>> 権威性アップ&簡易的なLLMO対策無料チェックリストはこちら