前回の記事では、自社サイトだけでは不十分な理由と、第三者からのポジティブな言及(サイテーション)を増やすためのソーシャルリスニング・PR活動の重要性を解説しました。
しかし、「もっとコンテンツを作らなければ」と焦る前に、立ち止まって考えてほしいことがあります。
この10年以上、「SEO対策をすべきだ」と言われ続け、多くの企業が何らかのコンテンツを発信してきたはずです。
サイトのブログ記事、SNSへの投稿、施工事例、お客様の声などは、AI検索時代に「無駄になった資産」ではありません。
問題は、「どのAIに向けて」「どのプラットフォームで」公開されているかです。
ここを整理して再配置するだけで、同じコンテンツがAIに引用される可能性は大きく変わります。
この記事では
「SNSに毎日投稿しているのに、ChatGPTで自社が全然出てこない」「サイトの記事は書いてきたが、AI検索での露出が弱い」といったSEOとLLMOの対策を検討している経営者向けに、これまでのコンテンツ資産をAI引用につながる形で「循環」させる具体的な方法を無料で公開しています。
今回は「コンテンツの循環」という考え方と、プラットフォームごとのAI到達範囲の違いを、第三者調査・公式データの根拠とともに徹底解説します。
この記事でわかること
- なぜ「同じコンテンツ」でもAIに引用されるものとされないものがあるのか
- X(旧Twitter)・Meta(Facebook/Instagram)の投稿がChatGPTに届かない構造的な理由
- noteがChatGPTをはじめとするAIの引用上位ドメインである根拠
- X投稿をnote記事に「循環」させてAI引用率を高める具体的な手順
- 自社のコンテンツ資産をどう棚卸しし、どう再配置するか
AIはどこを読んでいるのか:プラットフォームとAIの「閉じた関係」
InstagramやXで毎日投稿しているのに、ChatGPTで自社について聞いても全然出てきません。コンテンツが足りないのでしょうか?
コンテンツ量の問題ではありません。投稿しているプラットフォームと、引用しているAIが、構造的に『別の閉じた世界』にあるからです。ChatGPTはXの投稿を読めない状態になっています。
AIが回答を生成する際に参照できるコンテンツは、「そのAIのクローラー(収集ロボット)がアクセスできるプラットフォームかどうか」で決まります。
2024〜2025年にかけて、主要SNSプラットフォームはそれぞれ「自社AIとの独占的なデータ関係」を確立しています。これにより、「どこに投稿したコンテンツが、どのAIに届くか」が明確に分断されています。
X(旧Twitter):xAI・Grokとの独占関係
2025年3月28日、イーロン・マスク氏のAI企業xAIがX社を買収しました。これにより、XのデータはGrokが独占的に利用できる体制が正式に確立されました。

xAIがOpenAIや他のスタートアップ企業に対して持つ大きな利点の1つは、Xへのアクセス権です。Xが長年にわたって蓄積してきた膨大な投稿データは、AIトレーニングデータ獲得競争においてxAIに大きなアドバンテージをもたらします。
📎引用元: TechCrunch「Elon Musk says xAI acquired X」(2025年3月29日)
さらにXの利用規約は、自動アクセス・データ収集・スクレイピングを「いかなる形式・目的においても」禁止しています。
資料②

X Blocks AI Training on Tweets in Data Power Move Amid Generative AI RaceX社、生成型AI開発競争の最中、データ活用の一環としてツイートを用いたAIトレーニングをブロック
📎引用元: Medium / Artificial Synapse Media(2025年6月)
上記内容からもわかるようにXへのOpenAI(GPTBot)・Anthropic(ClaudeBot)・Google(Googlebot)等のAIクローラーは構造的にブロックされており、X上のコンテンツはGrok以外のAIの引用対象にならない可能性が高いのです。
Meta(Facebook・Instagram):Meta AIに閉じたデータ
FacebookやInstagramの投稿は、基本的にログイン認証が必要な環境で公開されており、外部のAIクローラーはアクセスできません。
Instagramは、ログインしないと見られないコンテンツが大半なため、構造上AIがアクセスできない、しにくいという状態になっています。
その為、Facebook・Instagramのコンテンツは、Meta AI(LLaMA)が学習・参照する一方、ChatGPTやGeminiがこれらの投稿を引用元として参照することは難しいのがわかります。
LLMO研究所で各SNS・主要媒体がgoogleや chatGPTへの露出をどのくらい露出する可能性があるのか初心者でもわかるように早見表を作成しました。
プラットフォーム別「どのAIに届くか」一覧
| プラットフォーム | 主に届くAI | ChatGPTへの露出 |
|---|---|---|
| X(旧Twitter) | Grok(xAI) | ❌ 不可(利用規約・robots.txtでブロック) |
| Facebook / Instagram | Meta AI(LLaMA) | 🔺 難しい(ログインウォール) |
| note | ChatGPT・Gemini・Perplexity等 | ✅ 可能(日本国内の上位引用ドメイン) |
| 自社ウェブサイト・ブログ | ChatGPT・Gemini等 | ✅ 可能(クローリング対象) |
| YouTube | ChatGPT・Gemini等 | ✅ 非常に高い |
| Wikipedia | ChatGPT・Gemini等 | ✅ 非常に高い |
作図:LLMO研究所
この表が示すように、XとMeta系のコンテンツは、それぞれの純正AIには届く一方、ChatGPTやGeminiの引用対象にはなりにくいです。どれだけ投稿を積み上げても、プラットフォームの構造上、ChatGPTへの露出にはつながらないのです。
「コンテンツ循環」という考え方
では、これまでXやInstagramに投稿してきたコンテンツは、AI検索では全部無駄になってしまったのでしょうか…?
いいえ。それらは『一次情報の生データ』として価値があります。重要なのは、そのコンテンツをChatGPTなどが読める場所に『変換して再配置』することです。これが『コンテンツの循環』という考え方です。
「コンテンツの循環」とは、すでに発信済みのコンテンツ資産を、AIに引用される可能性が高いプラットフォームや形式に変換・再投稿する考え方です。ゼロから作るのではなく、「手元にある素材を料理し直す」イメージです。
Googleが定めるE-E-A-T(経験・専門性・権威性・信頼性)において、「経験(Experience)」とは、コンテンツ作成者が実際にその事象を体験しているかを問うものです。
X投稿や施工写真・過去のブログ記事は、まさにこの「経験」の一次情報です。それをAIが読める形に整えることが、循環の本質です。

コンテンツは、実体験や深い知識(たとえば、実際に商品やサービスを使用したり、ある場所を訪れたりした経験に基づく特別な知識)を明確に示していますか。
📎引用元: Google Search Central – Creating Helpful, Reliable, People-First Content
具体的な循環パターン①:X投稿 → note記事化
最も実践しやすい循環の一例が、X(旧Twitter)の投稿をnote記事として再構成・連続投稿する方法です。
なぜnoteをLLMO研究所が推しているのかを解説していきます。
以前のLLMO研究所で解説した【最新版】日本のAI検索 引用ドメインの新常識|LLMO時代の信頼性構築法記事の中に掲載したように、チャットgptドメインランキング日本版からもわかるのは、
チャットGPTは、権威のあるサイト(Reddit やWikipedia )、よく知られている企業公式情報(PR TIMES )、個人の体験談系ブログ系(Ameblo、note)、を好む傾向にあるのがわかります。


つまり、Xに投稿し続けても届かなかったChatGPTに、同じ内容をnote記事として再構成して投稿することで、引用対象になり得るのです。
下記のような方法でx投稿もnoteで循環させることが可能です。
X投稿 → note循環の具体的な手順
| STEP | 作業内容 | ポイント |
|---|---|---|
| 1 | X投稿の棚卸し | 反応が良かった・専門性が高い投稿を抽出する |
| 2 | テーマ別にグルーピング | 同テーマの投稿10〜20本を1記事に束ねる |
| 3 | note記事として再構成 | 見出し・根拠・補足説明を加えて800〜2000字に整える |
| 4 | noteに継続投稿 | 月2〜4本を目安に、専門テーマを軸に連続投稿する |
| 5 | 自社サイトへの内部リンク設置 | noteから自社サービスページへの導線をつくる |
循環させていくことでこれまでの活動が価値として循環するようになります。
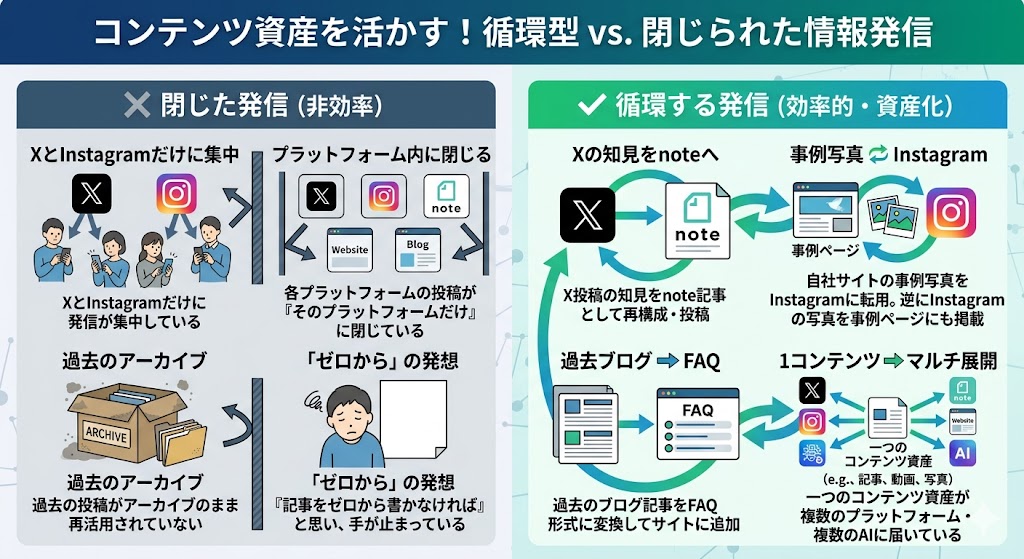
コンテンツ資産の棚卸しと循環パターン一覧
X投稿以外にも、これまで作ってきたコンテンツはいくつかあります。それらも循環できますか?
もちろんです。まず手元にある資産を種類別に棚卸しして、それぞれの『変換先』を決めることが重要です。
下記は、LLMO研究所が整理した「コンテンツ資産の循環パターン一覧」です。
| 元のコンテンツ資産 | 変換・再配置先 | AIへの効果 |
|---|---|---|
| X投稿(専門知識・知見) | note記事として再構成 | ChatGPT・Gemini等の引用対象になる |
| Instagram投稿(施工写真等) | 自社サイトの事例ページに再掲載 | エンティティ(人物・地域・製品)の強化 |
| 過去のブログ記事 | FAQページとして再構成 | AIが読み取りやすい「問いと答え」形式に変換 |
| お客様の口コミ・感想 | Googleビジネスプロフィールへの誘導・掲載 | サイテーション(外部評判)として機能 |
| 社内マニュアル・蓄積知識 | 専門コラム記事として公開 | トピカル・オーソリティの強化 |
どの資産も「一次情報」としての価値があります。それをどの形式に変換し、どのプラットフォームに届けるかを設計することが、循環の核心です。
『循環』という考え方はわかりました。何から手をつければいいですか?
まずは自社のコンテンツ資産の棚卸しから始めましょう。以下のチェックリストで、どの資産がどこに眠っているかを確認してください。
| ✓ | チェック項目 | 対応施策 |
|---|---|---|
| ☐ | 過去のX投稿のうち、専門性・反応が高いものをリストアップしている | コンテンツ棚卸し |
| ☐ | noteアカウントを開設し、専門テーマで月2本以上投稿している | note展開 |
| ☐ | Instagram・Facebook投稿の写真・テキストを自社サイトの事例ページで再活用している | コンテンツ循環 |
| ☐ | 過去のブログ記事をFAQ形式に変換して自社サイトに追加している | コンテンツ変換 |
| ☐ | お客様の声・口コミをGoogleビジネスプロフィールに集めている | サイテーション獲得 |
| ☐ | 各コンテンツに著者名・資格・公開日が明記されている | E-E-A-T強化 |
| ☐ | note記事から自社サービスページへの内部リンクを設置している | 内部リンク設計 |
| ☐ | ChatGPT・Perplexityで自社名・サービス名を検索し、引用されているか確認している | LLMO計測 |
まとめ
今回解説した「コンテンツ循環」の考え方を整理します。
AI検索時代のコンテンツ戦略 3つの原則
- プラットフォームによってコンテンツが届くAIは異なる
→ Xの投稿はGrokのみなど、ChatGPTへの露出には、アクセス可能なプラットフォームへの再配置が必要。
- これまでのコンテンツ資産は「一次情報の生データ」として活きる
→ Xの投稿・Instagramの写真・過去のブログ記事は、ゼロから作るより価値ある経験の記録。捨てるのではなく、変換する。
- 「変換×再配置」がAI引用率を高める鍵
→ note記事への再構成・FAQへの変換・自社サイトへの還流という「循環」で、同じ資産が複数のAIに届く状態をつくる。
AI検索時代に必要なのは「もっと作る」ではなく「うまく循環させる」発想の転換です。
手元にある資産を、AIに読まれる場所に届ける。
その設計こそが、2026年以降のAI検索で選ばれ続けるための本質的な戦略です。
LLMO対策は日々進化しており、最新の動向を把握することが不可欠です。
LLMO研究所が運営している無料メルマガでは、最新のAI技術動向やLLMO対策の実践事例を定期的に配信しています。
やっぱり時間がないしLLMO対策は難しそうですが、どうすればいいですか?
まずはLLMO研究所のメルマガに登録して短時間で最新情報をキャッチアップすることをお勧めします。
メルマガでは、AIアルゴリズムの変更点や最新の事例研究、成功事例などが詳細に解説されています。
これらの情報を活用することで、自社のLLMO戦略を常に最適な状態に保つことができます。
また、メルマガ限定の実践ワークショップや分析ツールの情報も提供されており、具体的な施策立案に役立てることができます。
無料ホワイトペーパーのご案内
LLMOの基本から実践まで、さらに詳しく学びたい方に向けて、LLMO研究所ではホワイトペーパーを無料で配布しています。
>> 権威性アップ&簡易的なLLMO対策無料チェックリストはこちら
LLMO対策の全体像を知りたい方へ
本記事で解説したコンテンツ循環戦略は、LLMO対策の一部です。より包括的な対策フレームワークについては、以下のホワイトペーパーで詳しく解説しています。




